

In every organization, data is everywhere. IoT, databases, data warehouses, filesharing platforms, SCADA systems, GIS tools, CAD files and proprietary enterprise systems. The level of fragmentation is far beyond what most teams can manage effectively.
Mid size companies typically operate between 50 and 200 different data systems. Large enterprises work with 200 to 1,000 systems. Many Fortune 500 companies exceed 2,000 applications and data sources across their environments.
Yet even with this massive data footprint, answers are still hard to obtain.
Sixty eight percent of companies report data silos as their top challenge in 2024. That number has grown seven percent since last year. While data volume increases at an exponential rate, with more than 83 percent of organizations processing terabytes or petabytes daily, metadata remains inconsistent, quality signals are incomplete, and governance is reactive.
Seventy eight percent of IT and data teams report difficulties orchestrating workloads across systems, dealing with tool sprawl, and handling data variety and volume. Even simple business questions become difficult to answer.
Where is the data needed?
Can it be trusted?
Who else is using it?
How do we act on it?
Integration work has become a critical bottleneck. Seventy one percent of organizations take more than three weeks to complete a single integration. Building a reliable data pipeline can take up to twelve weeks. Enterprises spend between sixty and eighty percent of project time on integration and preparation rather than analysis.
Traditional solutions such as catalogs, lineage tools and glossaries provide documentation but do not solve access, execution or cross platform orchestration. They rarely offer real time insight. They do not highlight emerging risks. They do not explain how data should be used.
With the data integration market growing at 13.8 percent CAGR to reach 25.69 billion USD by 2029, and more than half of data professionals identifying AI supported integration as a priority, it is clear that conventional methods are not sufficient.
Advanced query optimization can deliver up to seven times faster performance compared to traditional cost based designs. Federated processing can reduce infrastructure costs by more than 35 percent and save more than 200,000 USD annually.
A smart data concierge service solves this by transforming fragmented data landscapes into intelligently connected, query ready ecosystems that deliver answers instead of static catalogs.
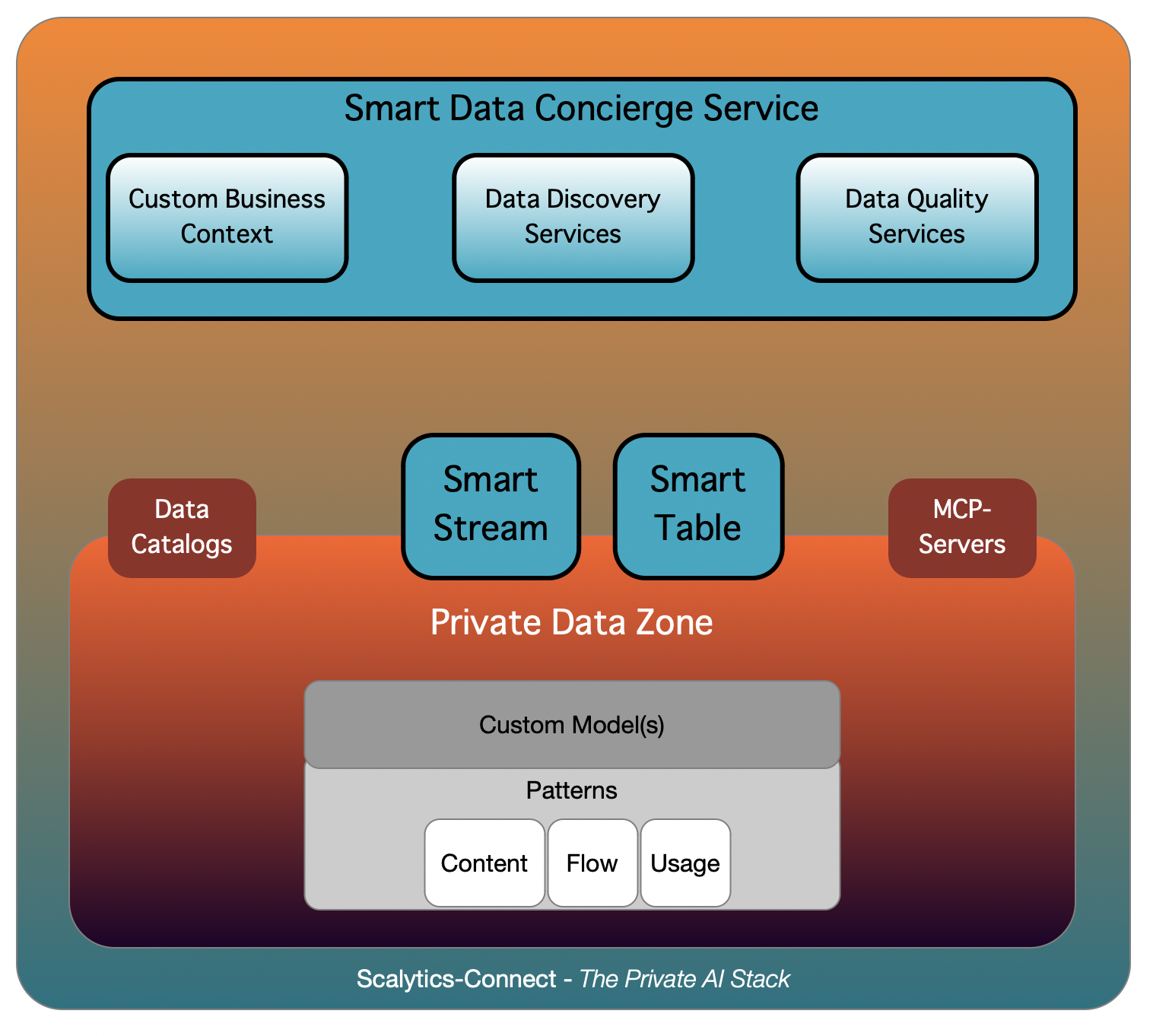
Smart Data Concierge Service
This is the top layer of the architecture, where business users interact with data through natural questions rather than manual retrieval or ticket requests. It provides several intelligent functions.
Custom Business Context
Your organizational structure, terminology and domain concepts guide every interaction. Relevant datasets and signals are connected into the assistant's context to improve precision.
Data Discovery Services
The system identifies the right data source for each question. It learns how to use distributed assets efficiently and safely.
Data Quality Services
Trust and transparency are built through quality scoring, lineage visibility, access control and audit logs.
This layer becomes the entry point to a Deep Search like experience that produces meaningful and actionable answers without query writing. It behaves like a personal data concierge fully aware of your environment.
Smart Stream and Smart Table Services
At the core of the system are two real time integration services that provide unified execution across streaming and batch data.
Smart Streams
Smart Streams support event driven use cases such as anomaly detection, monitoring and real time dashboards. Continuous learning enables pattern recognition without additional engineering overhead.
Apache Kafka and Apache Flink power this subsystem, providing scale, reliability and efficient stateful processing.
Smart Tables
Smart Tables create virtual, federated views across distributed systems without copying data. They enable direct querying, modeling and decision support.
Apache Wayang is the core execution engine for this subsystem, providing cross platform query planning and federated execution across heterogeneous stores.
Both modules operate entirely inside your private data zone. They maintain compliance, preserve sovereignty and avoid unnecessary duplication. They connect to existing catalogs and can integrate with MCP servers for secure access.
Custom Models and Usage Patterns
The foundation of the system supports enterprise specific logic, private algorithms and usage behavior. You can define:
- Content patterns that map entities, datasets and sources
- Flow patterns that reflect consumption rates and timing across systems
- Usage patterns that track who uses which data, for what purpose and in which context
This enables proactive capabilities such as fraud detection, lifecycle cost analysis and consumption optimization without replicating or centralizing data. The approach is independent of your underlying technology stack. It wraps around your environment and simplifies navigation by focusing on outcomes rather than infrastructure management.
How To Build Your Own Data Concierge: 3 Steps
Traditional integration approaches slow enterprises down. Many organizations require six months for integrating enterprise data sources. Pipeline creation alone can take twelve weeks, which is unsustainable in fast moving markets.
The business impact of effective integration is clear. Organizations with strong integration frameworks report lower churn by 58 percent, new market expansion by 52 percent and higher close rates by 59 percent.
With 83 percent of teams listing integration as a primary priority, the question is not whether to modernize. The question is how to move faster.
Step 1: Activate Smart Streams and Smart Tables
Begin by federating core business datasets using the Smart Streams and Smart Tables capabilities provided by Scalytics Federated.
This gives immediate access to distributed data where it already lives.
No migrations.
No centralization.
No waiting for infrastructure.
Real deployments consistently demonstrate more than 35 percent cost savings and more than 200,000 USD in annual reductions when compared to centralized ETL based architectures.
Step 2: Integrate Business Context and Quality Signals
Add organizational context, quality rules and priority structures.This enables the Smart Data Concierge Service to deliver guidance rather than raw data. It addresses the challenges that 78 percent of data teams face with orchestrating data across systems and tools.ML based optimization can improve runtime by up to seven times compared to traditional approaches.
Step 3: Deploy Your Assistant
With unified execution and business context in place, you can deploy your private AI and data assistant. It answers questions, identifies problems, recommends actions and surfaces insights across domains.This reduces dependency on scarce engineering resources and improves time to value for business teams.
Smarter Questions, Faster Answers
The future of enterprise data is not only about access. It is about empowerment.
While most organizations operate hundreds of disconnected systems and spend months integrating data, Scalytics Federated helps you move from fragmented visibility to intelligent federation, from reactive governance to proactive insight and from static documentation to a living, learning assistant.
In environments where speed defines competitive advantage, the organizations that unify streaming and batch intelligence first will lead.
Sources:
About Scalytics
Our founding team created Apache Wayang, the federated execution framework that lets computation run where the data lives and dramatically reduces unnecessary data movement.
We also built and maintain kafSCALE, a high-performance, Kafka-compatible streaming platform designed for Kubernetes and object storage. It delivers elastic scale without broker complexity or lock-in.
Our mission: Keep data in place. Bring compute to the data. Enable secure, sovereign, and production-ready AI operations.