

Most MCP + Kafka integrations described online are theoretical. This one is not. KafScale ships a production MCP server - kafscale-mcp - that exposes your streaming cluster as structured tools any AI agent can call: list topics, inspect consumer lag, query metrics, describe group state. The entire stack runs locally with a single docker compose up. This article walks through how the architecture works, what the agent can see, and how to wire it up.
The Architecture
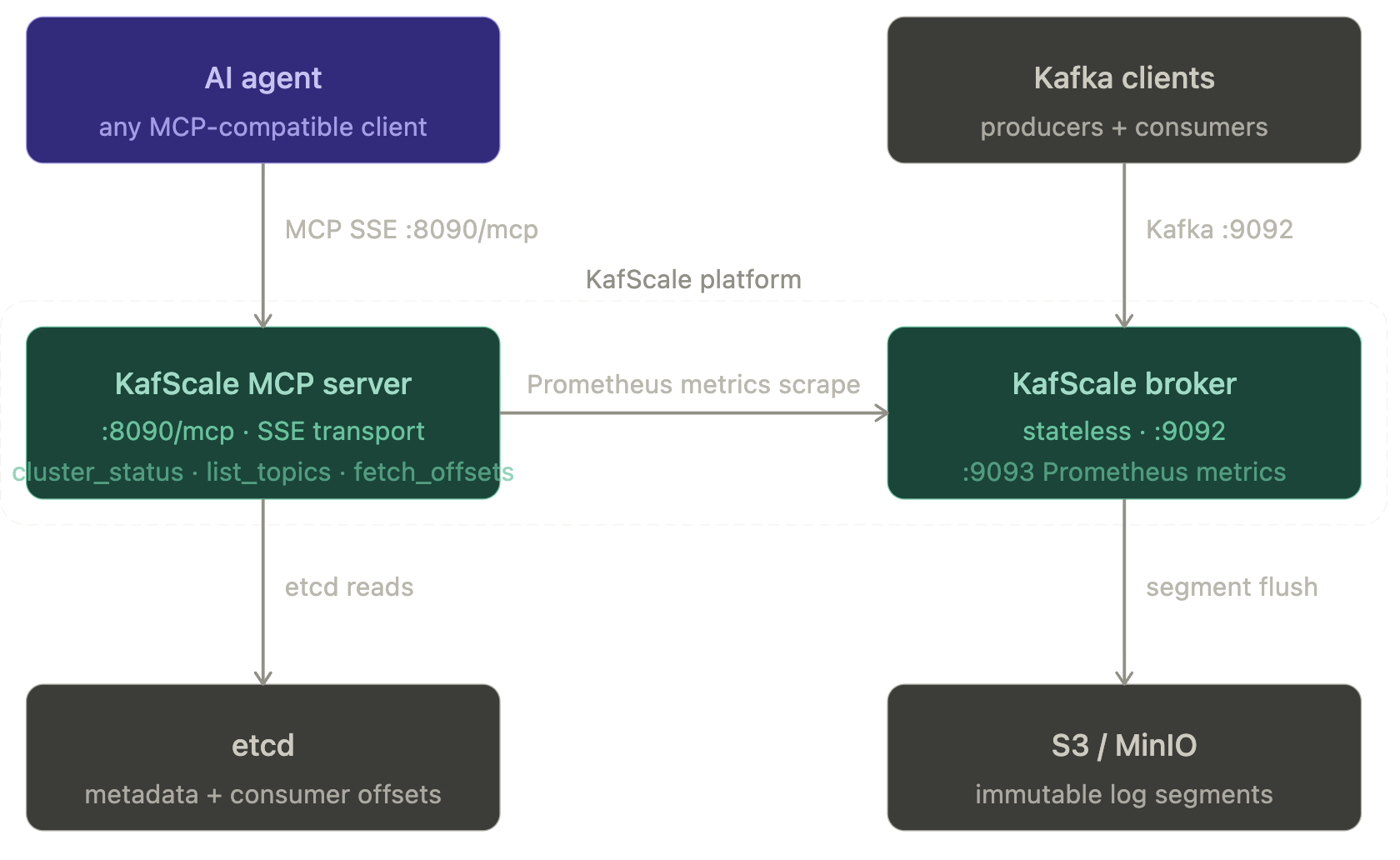
The diagram below shows the three-layer stack. The agent layer (any MCP-compatible client) talks exclusively to the MCP server over SSE — it never touches the Kafka data plane. The MCP server reads cluster metadata from etcd and scrapes the broker's Prometheus endpoint. The streaming layer handles Kafka protocol traffic independently.
Core components
1. KafScale MCP server
kafscale-mcp runs as a standalone service. It exposes a read-only tool surface at :8090/mcp using MCP streamable HTTP (SSE transport). Tools available in v1: cluster_status, cluster_metrics, list_topics, describe_topics, list_groups, describe_group, fetch_offsets, describe_configs. The server talks to etcd for metadata and scrapes the broker's Prometheus endpoint for real-time metrics. It is intentionally decoupled from brokers — no MCP logic runs inside the broker process, so the streaming data plane is never exposed to the agent.
2. KafScale broker
Brokers are stateless. They handle Kafka wire protocol at :9092 and flush immutable segments to S3 (or MinIO locally). There is no local disk state, no partition rebalancing, no replica movement. etcd holds topic metadata, consumer group state, and offsets. Broker failures are scheduling events, not recovery operations.
3. etcd
The only stateful component in the stack. Stores topic metadata, partition assignments, and consumer group offsets. Both the broker and the MCP server read from etcd. In production, back this up — it is the authoritative state for your cluster.
4. Apache Wayang execution
For analytical workloads that need to run against streaming data, Wayang execution plans operate inside the secure perimeter. Because the Scalytics team created the technology that became Apache Wayang, this is the processing foundation for running complex cross-platform workloads. KAFSQL — KafScale's SQL processor — can query segment data directly from S3 without touching broker resources.
A more detaiiled architecture in a regualted environment is also straight forward:

Core Components and Their Roles
1. MCP Server (Green)
The MCP server, implemented in Python, forms the backbone of the system. It integrates with data collections such as SQL databases, S3 objects, key-value stores, MongoDB, or existing client systems. Its modular design enables smooth integration across diverse environments. The server acts as the controlled interface for all incoming requests.
2. Internal Processing Layer (Blue)
This processing layer manages intermediate results using structured prompts and controlled execution flows. Sensitive data is processed within strict boundaries, forming a secure execution perimeter. This layer ensures that raw data never leaves its origin and that all transformations occur locally.
3. RAG Tool
Behind the MCP server runs a Retrieval-Augmented Generation module. It filters, tracks, and validates outputs according to client-defined rules. Outputs pass through the governance controls defined by the Agent Context Protocol (ACP), ensuring compliance and preventing sensitive data from leaving the secure perimeter.
4. KafScale as AI Agent Backbone
KafScale enables high-throughput and fault-tolerant communication for intermediate results. Its durability and delivery guarantees provide reliable real-time message flow between components. This ensures the system can scale under heavy workloads without compromising performance.
5. Wayang Plan Execution
Execution plans based on Apache Wayang operate entirely inside the secure perimeter. Because the Scalytics team originally created the technology that evolved into Apache Wayang, this execution model forms the analytical foundation for running sensitive workloads. Wayang plans handle computation while ensuring data locality, passing intermediate results through Kafka for downstream processing or client responses.
How It Works
The architecture is designed so that sensitive data stays where it is created. Instead of moving data between environments, the system uses local Large Language Models or Specialized Language Models that run inside the secure execution perimeter with locked-away data. Models do not expose the underlying data. Guardrails defined through ACP monitor and restrict agent behavior, ensuring no unauthorized information leaves the controlled environment.

Client Requests
A client sends a query or task to the MCP server. The server orchestrates access to data sources or intermediate results while remaining inside the secure perimeter.
Secure Data Processing
The MCP server retrieves required inputs or invokes the RAG tool. All data handling follows ACP governance rules. Processing occurs locally and adheres to compliance requirements.
Real-Time and Ad-Hoc Processing
The system supports real-time and ad-hoc requests. Wayang plans execute analytical tasks at the edge. Results flow through Kafka for downstream consumption.
Filtered Outputs
Outputs undergo strict filtering to ensure only approved information is returned to the client. ACP governance ensures the output matches allowed usage contexts.
Run it locally in five minutes
Go to https://github.com/KafScale/platform or follow the quickstart. The full stack - MinIO (local S3), etcd, KafScale broker, and the MCP server - starts with:
make demo-platformOnce healthy, your Kafka bootstrap is localhost:9092 and your MCP endpoint is http://localhost:8090/mcp. Connect any Kafka client or producer. Then connect your MCP client.
Connect Claude Desktop
Add this to ~/Library/Application Support/Claude/claude_desktop_config.json:
{
"mcpServers": {
"kafscale": {
"type": "http",
"url": "http://localhost:8090/mcp",
"headers": {
"Authorization": "Bearer local-dev-token"
}
}
}
}
What you can ask the agent
Once connected, the agent has structured access to your cluster state. Some examples:
"List all topics and their partition counts"
"Show me consumer lag for the orders consumer group"
"What is the current produce throughput in messages per second?"
"Are there any consumer groups with lag above 10,000 on any partition?"
"Describe the retention config for the payments topic"
"What is the S3 latency and error rate right now?"
All reads. The agent cannot produce messages, delete topics, or modify configuration — by design. Mutation tools are on the KafScale roadmap behind RBAC and dry-run mode.
Why It Matters
Compliance at Scale
The architecture aligns with regulations like GDPR and HIPAA. Sensitive data remains inside a controlled execution boundary, reducing the risk of exposure.
Developer-First Flexibility
With wide compatibility and modular components, the framework integrates into existing infrastructures without unnecessary overhead.
End-to-End Security
ACP and the secure execution perimeter ensure that data never leaves its origin environment. All interactions are monitored, filtered, and traceable.
High Scalability
Kafka and modular processing components allow the system to support heavy data flows and complex analytical workloads.
Real-World Applications
This architecture is suited for environments where security, compliance, and real-time performance intersect, such as:
- Sensitive financial data analysis under strict regulatory requirements
- Industrial monitoring and analytics for operational efficiency
- HIPAA-compliant medical data processing
Key Technical Highlights for Developers
- Optimized Message Flow: Kafka provides fault-tolerant, real-time communication with low latency.
- Dynamic Query Handling: Ad-hoc and real-time requests are processed securely without exposing underlying data.
- Wayang Plans: Execution plans optimize workloads while maintaining data locality and security.
- Integration-Ready: The MCP server supports plug-and-play integration with client environments.
Summary
KafScale's MCP server is the only native MCP integration in the S3-native Kafka space. The combination - stateless brokers, etcd-backed metadata, Prometheus metrics, and a decoupled MCP observability layer - means AI agents can inspect and reason over your streaming infrastructure without the data plane being involved at all. For organizations that can't centralise data (regulated industries, multi-party environments, on-premise requirements), this architecture means the agent comes to the data rather than the other way around. The docker-compose above is the fastest path to testing this on your own cluster topology.
For more information or to explore how this architecture can support your workflows, get in touch.
About Scalytics
Our founding team created Apache Wayang, the federated execution framework that lets computation run where the data lives and dramatically reduces unnecessary data movement.
We also built and maintain kafSCALE, a high-performance, Kafka-compatible streaming platform designed for Kubernetes and object storage. It delivers elastic scale without broker complexity or lock-in.
Our mission: Keep data in place. Bring compute to the data. Enable secure, sovereign, and production-ready AI operations.